





数据与流程–因子投资方法与实践之案例实现之二
发布日期:2022-03-20 19:06 点击次数:183
Table of Contents数据与流程 – 因子投资方法与实践之案例实现之二引言数据源工具函数量价数据处理财务数据处理数据与流程 – 因子投资方法与实践之案例实现之二引言石川博士的书 《因子投资方法与实践》,说实话,当阅读完第二章,第三章的时候,个人感觉是不太好的,首先在于文章的内秉逻辑,先讲三种因子回归方法,然后再去讲数据源与数据处理,这与主流的多因子研究的流程是倒序的;其次,可能作者是做学术出身,对于计量经济学的种种内容,直接套用了他所引用的国外课程的内容与结论,没有公式的推导,反而是公式的堆叠与结论的堆叠,最后三种分类,时序回归,截面回归到 Fama-Macbeth 回归,可能笔者非计量经济学出身,对于石川博士书中的论述,实在感觉难以 “下咽”,反复阅读几遍之后,总算有点心得,心中对那些几天读完石川博士书的人是万分佩服,笔者可能就是传说中的 “菜鸟” 来着吧。不管如何,“菜鸟” 也想飞,缺乏前辈指引,那也只能自行摸索体会。这里,笔者就按照 “菜鸟” 的思维去重新梳理书中的逻辑与处理方式,并加上笔者的一些变通手段。不同于原书中的先讲回归,再讲数据的方式,笔者这里先讲数据与处理,并以代码的方式,去实战一遍书中的案例,说来惭愧,对于书中的财务数据精确处理,笔者还是颇废了一番心思,方得到稍微过得去的精确回溯的方式,在下文中,笔者都会一一道来,也希望读者们能有所收获。数据源在进行多因子分析的过程中,最最开始,必然是数据源的选择,没有基础数据,一切都成了无根之木。在数据源选择上,考虑到很多量化爱好者确实没有大型机构的财大气粗,可以毫无顾忌的使用 wind,聚源,天软等数据,笔者尽可能去使用免费,便宜 (财务数据而言,符合要求的免费数据源笔者并没有找到) 的数据源。自从聚宽转型为资管为主,米筐也对模拟交易进行收费,商业软件上可以免费使用的量化框架,目前貌似也只剩掘金量化这根独苗了,每日 800W 条的限制,一般能满足普通爱好者需求了,但是,掘金在基本面数据上做的确实比较差,可能也与他们公司定位有点关系;免费的数据源来讲,笔者还是推荐 QUANTAXIS,基于通达信的数据本地化方案,绝大多数需要量价数据的时候,足以满足需求,在换手率等数据上,可能还得配合其他商业软件使用,而对于财务数据,如果不做回测的话,QUANTAXIS 直接可以拿到通达信能拿到的财务数据,还是相当可以的,而如果要进行回测研究,QUANTAXIS 也不够了,主要问题在于,其保存的本地数据是以财务报告期为准的,我们无法得知上市公司详细的财务报告发布时间,而且如果上市公司的财务数据进行修改的话,那么通达信也是覆盖保存的,原始数据就无法拿到了;因此,如果需要精准的财务数据,只能去花钱购买了,但是,传统的商业软件,譬如 wind,聚源等,动辄几万,十几万一年,对于普通爱好者,门槛实在太高了,综合考量,也就 tushare可堪一用,赞助了 500 块之后,基本上 tushare 所有的接口都可以使用了,下面所有关于财务数据的处理,也全部基于 tushare。工具函数针对不同数据源对于股票代码不同的输入方式,笔者这里直接整合了常用的数据接口需要的股票代码格式化函数,支持包括聚宽,万得,掘金,QUANTAXIS,tushare,招商证券的 Blade 等股票格式化代码from typing import Union, List, Tuple
from functools import partial
def hc_fmt_symbol(tickers: Union[str, List, Tuple], style: str = None):
"""
根据 style 格式化对应标的代码, 仅支持 A 股股票
---
:param tickers: 股票代码或股票代码列表
:param style: 股票代码风格,支持主流的数据源与量化框架
"""
def _fmt_symbol(symbol: str, style: str):
symbol = pattern.findall(symbol)[0]
if style in ["jq", "joinquant", "聚宽"]:
return symbol + ".XSHG" if symbol[0] == "6" else symbol + ".XSHE"
if style in ["wd", "windsymbol", "万得"]:
return symbol + ".SH" if symbol[0] == "6" else symbol + ".SZ"
if style in ["ts", "tushare", "挖地兔"]:
return symbol + ".SH" if symbol[0] == "6" else symbol + ".SZ"
if style in ["gm", "goldminer", "掘金"]:
return "SHSE." + symbol if symbol[0] == "6" else "SZSE." + symbol
if style in ["ss", "skysoft", "天软"]:
return "SH" + symbol if symbol[0] == "6" else "SZ" + symbol
if style in ["cms", "blade", "招商"]:
return symbol + "@SSE" if symbol[0] == "6" else symbol + "@SZE"
else:
return symbol
if isinstance(tickers, str):
tickers = [tickers]
pattern = re.compile(r"\d+")
fmt_symbol = partial(_fmt_symbol, style=style)
tickers = list(map(fmt_symbol, tickers))
return tickers
在多因子处理过程中,通常需要进行行业中性化,不同股票由于行业不同,会有完全不同的财务表现,因此,对于多因子分析,行业信息非常重要,笔者这里直接采用了 tushare 数据源,支持申万一、二、三级分类,tushare 数据获取接口每分钟最多五百次查询,笔者这里用了比较简陋的处理方式 def hc_get_industry(
tickers: Union[str, List, Tuple],
industry: str = "sw_l1",
token: str = "TUSHARE 的 TOKEN"
) -> pd.DataFrame:
"""
获取股票对应的行业分类与行业名称
FIXME: 这里默认按照最新的行业分类
---
:param tickers: 股票代码或股票代码列表
:param industry: 行业分类,目前仅支持申万行业三级分类,对应参数依次为 "sw_l1", "sw_l2" 和 "sw_l3"
"""
try:
import tushare as ts
except:
raise ModuleNotFoundError("[MODULE ERROR]\t没有找到 tushare 模块")
if industry.lower() not in ["sw_l1", "sw_l2", "sw_l3"]:
raise ValueError("[VALUE ERROR]\t行业信息仅支持申万分类")
)
# 对应分类的行业信息
sw_industry = pro.index_classify(level=industry.upper()[3:], src='SW')
# 行业信息数据格式设置
ret_info = pd.DataFrame(
columns=["symbol", "industry_code", "industry_name"])
for ticker in tickers:
try:
ticker_industry = pro.index_member(ts_code=ticker)
except:
print("[WARNING]\t股票 {} 查询失败,等待 65 秒后重试".format(ticker))
time.sleep(65)
try:
ticker_industry = pro.index_member(ts_code=ticker)
except:
print("[WARNING]\t多次查询股票 {} 失败, 设置为 None".format(ticker))
,
)
.iloc[-1]
.index_code
)
industry_name = (
sw_industry.loc[sw_industry.index_code ==
industry_code].iloc[0].industry_name
)
except:
print("[WARNING]\t股票 {} 没有查询到对应的行业信息, 设置为 None".format(ticker))
industry_code = None
industry_name = None
ret_info = ret_info.append(
{
"symbol": ticker,
"industry_code": industry_code,
"industry_name": industry_name,
},
ignore_index=True,
)
return ret_info.reset_index(drop=True)
获取对应股票的财务报表时间发布信1息 def hc_get_report_date(
tickers: Union[str, List, Tuple],
start_date: Union[str, pd.Timestamp],
end_date: Union[str, pd.Timestamp],
token: str = "TUSHARE TOKEN",
) -> pd.DataFrame:
"""
获取对应股票的财务报表发布时间信息,包括股票代码, 计划披露时间,实际披露时间,对应报告期
---
:param tickers: 股票代码或股票列表
:param start_date: 搜索起始时间
:param end_date: 搜索结束时间
"""
# Tushare 配置
try:
import tushare as ts
except:
raise ModuleNotFoundError("[MODULE ERROR]\t没有找到 tushare 模块")
ts.set_token(token)
pro = ts.pro_api()
# 入参格式化
if isinstance(tickers, str):
tickers = [tickers]
tickers = hc_fmt_symbol(tickers, "ts")
start_date = pd.Timestamp(start_date).strftime("%Y%m%d")
end_date = pd.Timestamp(end_date).strftime("%Y%m%d")
# 返回值数据格式设置
ret_df = pd.DataFrame(
columns=[
"symbol", # 股票代码
"ann_date", # 最新披露公告日
"report_date", # 报告期
"plan_date", # 计划披露日期
"actual_date", # 实际披露日期
"modify_date" # 披露日期修正
])
# 报告期与时区设置,默认东八区
report_dates = ["0331", "0630", "0930", "1231"]
# 找到最接近的可能报告期,这里采用最近的两期报告期
start_report_date = None
end_report_date = None
if arrow.get(start_date, tzinfo=tzinfo) <= arrow.get(start_date[:4]+report_dates[0]):
start_report_date = str(int(start_date[:4]) - 1) + report_dates[2]
elif arrow.get(start_date, tzinfo=tzinfo) <= arrow.get(start_date[:4]+report_dates[1]):
start_report_date = str(int(start_date[:4]) - 1) + report_dates[3]
elif arrow.get(start_date, tzinfo=tzinfo) <= arrow.get(start_date[:4]+report_dates[2]):
start_report_date = start_date[:4] + report_dates[0]
else:
start_report_date = start_date[:4] + report_dates[1]
# 结束日期,找到最近一起的报告期
if arrow.get(end_date, tzinfo=tzinfo) <= arrow.get(end_date[:4]+report_dates[0]):
end_report_date = str(int(end_date[:4]) - 1) + report_dates[3]
elif arrow.get(end_date, tzinfo=tzinfo) <= arrow.get(end_date[:4]+report_dates[1]):
end_report_date = end_date[:4] + report_dates[0]
elif arrow.get(end_date, tzinfo=tzinfo) <= arrow.get(end_date[:4]+report_dates[2]):
end_report_date = end_date[:4] + report_dates[1]
else:
end_report_date = end_date[:4] + report_dates[2]
if (not start_report_date) or (not end_report_date):
raise ValueError("[ValueError]\t无法获取最近的报告日期,检查输入的日期格式")
# 配置对应日期内的报告期列表
report_dates_queried = []
if start_report_date[:4] == end_report_date[:4]:
idx_start = report_dates.index(start_report_date[4:])
idx_end = report_dates.index(end_report_date[4:]) + 1
report_dates_queried = list(
map(lambda x: start_report_date[:4] + x, report_dates[idx_start: idx_end]))
elif start_report_date[:4] < end_report_date[:4]:
diff_years = int(end_report_date[:4]) - int(start_report_date[:4])
idx_start_1 = report_dates.index(start_report_date[4:])
idx_end_1 = len(report_dates) + 1
report_dates_queried = list(
map(lambda x: start_report_date[:4] + x, report_dates[idx_start_1: idx_end_1]))
idx_start_2 = 0
idx_end_2 = report_dates.index(end_report_date[4:]) + 1
for i in range(1, diff_years+1):
cursor_year = int(start_report_date[:4]) + i
if cursor_year != int(end_report_date[:4]):
report_dates_queried += list(
map(lambda x: str(cursor_year)[:4]+x, report_dates))
else:
report_dates_queried += list(
map(lambda x: end_report_date[:4] + x, report_dates[idx_start_2: idx_end_2]))
def _get_total_disclosure_date(end_date: str = None):
try:
df_local = pro.disclosure_date(
end_date=end_date).rename(
columns={
"ts_code": "symbol",
"end_date": "report_date",
"pre_date": "plan_date",
})
return df_local
except:
raise ValueError("[ValueError]\t接口调用失败, 返回")
def _get_seperate_disclosure_date(ticker: str, end_date: str):
try:
df_local = pro.disclosure_date(
ts_code=ticker,
end_date=report_date).rename(
columns={
"ts_code": "symbol",
"end_date": "report_date",
"pre_date": "plan_date",
})
return df_local
except:
raise ValueError("[ValueError]\t单股票接口调用失败")
for report_date in report_dates_queried:
try:
df_tmp_1 = _get_total_disclosure_date(report_date)
except:
print("全量查询中...等待 65 秒")
time.sleep(65)
try:
df_tmp_1 = _get_total_disclosure_date(report_date)
except:
raise ValueError("[ValueError]\t接口调用连续两次出错,返回")
ret_df = ret_df.append(df_tmp_1, ignore_index=True)
extra_tickers = set(tickers).difference(set(ret_df.symbol.tolist()))
for ticker in extra_tickers:
try:
df_tmp_2 = _get_seperate_disclosure_date(ticker, report_date)
except:
print("个股查询中...等待 65 秒")
print("当前的report_date 为:", report_date)
time.sleep(65)
try:
df_tmp_2 = _get_seperate_disclosure_date(
ticker, report_date)
except:
raise ValueError("[ValueError]\t接口调用连续两次出错,返回")
ret_df = ret_df.append(df_tmp_2, ignore_index=True)
ret_df = ret_df[["symbol",
"ann_date",
"report_date",
"plan_date",
"actual_date",
"modify_date"]].loc[~ret_df.actual_date.isna()].loc[
(ret_df.actual_date >= start_date) & (ret_df.actual_date <= end_date)].reset_index(drop=True)
return ret_df
量价数据处理复权方式的选择: 从调仓模拟考虑,加入在对应历史时期,我们需要买入某支股票,那么,当给定金额的时候,实际能买入的股票数量必然是按照当时股价的实际价格计算出来的,而非前复权的价格。与此同时,在之后的调仓日,我们需要计算股票的收益率的时候,如果这过程中,股票发生了除权除息的情况,用非复权价格计算也必然是不对的。综上考虑,在处理多因子数据的时候,量价数据,以后复权方式为好,即在对应开仓的时候,以真实价格成交,在调仓日计算收益的时候,以定点 (开仓日) 后复权计算即可。QUANTAXIS 对于复权的处理方式是按照 wind 计算方式处理的,已经整合在对应的数据结构中,譬如,我们想拿到沪深 300 的从 2010 年到 2020 年的量价数据,可以按照下述代码处理 import QUANTAXIS as QA
import pandas as pd
code_list = QA.QA_fetch_stock_block_adv().data.loc['沪深300'].index.tolist() # 仅考虑当前的沪深 300 成分股
hfq_data = QA.QA_fetch_stock_day_adv(code=code_list,start='2010-01-01', end='2020-10-25').to_hfq().data # 获取沪深 300 的后复权数据
停复牌考虑: 如果 A 股特殊的制度,导致上市公司经常会以重大事项发布为由,进行停牌处理,这对于广大投资者而言其实并不合理。在对股票进行分析的时候,我们也需要对停牌时间过长的股票进行剔除,以免其对于我们的投资组合进行因子分析的时候,产生偏差,一个简单的处理方式,如果我们的投资组合是按月调仓的时候,那么每个月不少于该月所有交易日少两天即可。 trade_days= hfq_data.groupby(pd.Grouper(level=0, freq='M')).apply(lambda x: x.groupby("code").apply(len)) # 按月进行交易日统计
trade_days_threshold = hfq_data.groupby(pd.Grouper(level=0, freq='M')).apply(lambda x: x.groupby("code").apply(len)).groupby(level=0).max() - 2 # 过滤条件
trade_days_filter = trade_days.groupby(level=0).apply(lambda x: x >= trade_days_threshold.loc[x.name]) # 过滤
filter_codes = trade_days.loc[trade_days_filter] # 每个月交易日达标后的股票
财务数据处理 关于日期的说明不同上市公司的财务报表发布日期并不相同,然后对应每个财务报表,都会有一个报告期,一般而言,为一季报,半年报,三季报和年报,对应的报告期为 3 月 31 日,6 月 30 日,9 月 30 日以及 12 月 31 日。如果我们按照报告期去获取股票的财务数据,因为报告期与实际财报公布时间并不一致 (譬如当年的 4 月 30 日,A 公司发布了该公司去年年报以及今年一季报,在 3 月 31 号,我们实际上是获取不到对应的年报和一季报的)。因此,如何在历史回溯过程中找到合适的财务报表,是一个问题。 关于财报修正某些公司,由于会计准则变更或其他原因,会发布财报的修正报告,修正报告一般分为两种,一种是定期的 (不一定有修正), 譬如 2019 年年报发布的时候,对应上市公司会发布去年同期的财务数据,相比原始报告数据,可能此时的基准数据会有所变更;另外一种财报修正则是不定期修正,譬如柳工的 2018 年半年报,在 2018 年 8 月 30 日,公司发布了半年报的原始报告,之后,在 2018 年 9 月 29 日又发布了修正报告,如果我们在做历史回溯的时候,假设在 2018 年 8 月 31 日进行第一次调仓,显然应该按照 2018 年 8 月 30 日发布的财务数据进行计算;而如果到了 2018 年 9 月 30 日调仓的时候,我们就应该按照修正后的半年报数据进行处理。报告类型万得,tushare 等数据源,对于财务数据的修正,会进行类型的划分,笔者这里以 tushare 为例,tushare 官网对于财务数据类型划分如下:处理方式由上面论述可知,如果想在历史回溯中精确找到当前时间能拿到的最新数据,我们至少需要有两个类型数据类型为 1 的合并报表数据,这是上市公司最新报表数据类型为 5 的调整前报表数据,如果上市公司的财务数据发生变更,变更前的数据可以通过类型 5 来获取(可选) 如果当前时间周期到了基准数据发布时间之后,且需要用到基准数据,可以获取类型 4 的数据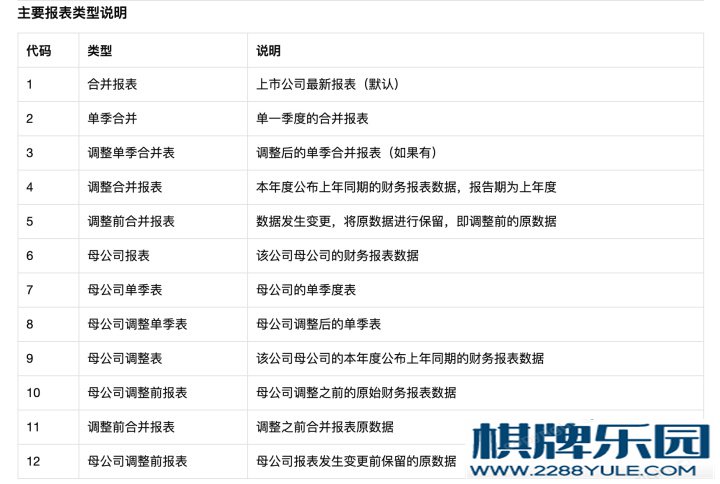 处理代码:笔者这里采用了比较偷懒和取巧的处理方式,具体步骤如下历史所有类型所有财物数据获取并合并 import tushare as ts
import pandas as pd
import time
from utils import hc_get_report_date
ts.set_token("TUSHARE TOKEN")
pro = ts.pro_api()
# 设置报告期
report_dates_tail = ["0331", "0630", "0930", "1231"]
,,
).strftime("%Y%m%d").str.slice(0, 4))))
report_dates = [y + d for y in years for d in report_dates_tail]
for i in range(1, 13):
exec(f"df_income_{i} = pd.DataFrame()")
for report_date in report_dates:
print(report_date)
for report_type in range(1, 13):
try:
exec(
f"income_{report_type} = pro.income_vip(period={report_date}, report_type={report_type})")
except:
print(
"[WARNING]\t income type-{report_type} 接口错误, 当前报告期为 {report_date}, 等待 65 秒后重试")
time.sleep(65)
try:
exec(
f"income_{report_type} = pro.income_vip(period={report_date}, report_type={report_type}")
except:
raise ValueError("[ERROR]")
exec(f"print(income_{report_type})")
exec(
f"df_income_{report_type} = df_income_{report_type}.append(income_{report_type})")
for report_type in range(1, 13):
exec(
f"df_income_{report_type}.to_csv('../data/income_{report_type}.csv', index=False)")
调仓周期的设置,按照每月末调仓 # 考察日期设置
start_date = "2010-01-01"
end_date = "2020-10-17"
)
对应调仓日,能获取最新的财务数据 # 对每个调仓日进行查询,判断对应日期,应该获取的财报类型
# 说明:柳工 (000528.SZ) 在 2018 年 8 月 30 日发布半年报,之后在 2018 年 9 月 29 号发布
# 修正报告,在 tushare 对应的财报发布日期分别为
# report_date(报告期), ann_date(最新披露公告日) ,plan_date(计划公告日) ,actual_date(实际公告日) ,modify_date(披露日期修正记录)
# 20180630 ,20180629.0 ,20180830 ,20180830 ,NaN
# 20180930 ,20180928.0 ,20181030 ,20181030 ,NaN
# ...
# 20190630 ,20190628 ,20190829 ,20190829, NaN
# 当调仓日处于 20180830 ~ 20180928 之间的时候,财报获取类型为 type-5 (调整前合并报表 数据发生变更,将原数据进行保留,即调整前的原数据)
# 当调仓日处于 20180928 ~ 20190829 之间的时候,财报获取类型为 type-1 (上市公司最新报表(默认))
# 当调仓日处于 20190829 之后,财报获取类型为 type-4 (本年度公布上年同期的财务报表数据,报告期为上年度)
# FIXME: 例外情况:不定期财报修正可能出现在下下期财报发布之后,由此造成类型判断错位,暂时没想到比较好的解决方案
df_income = pd.read_csv(
"../data/income.csv", dtype={"ann_date": str, "f_ann_date": str, "end_date": str}
) # 这里的 income.csv 为合并后的所有财务数据
results = {}
# for adj_date in pos_adj_dates:
for adj_date in ["20180731", "20180831", "20180930", "20181031"]:
# adj_date = adj_date.strftime("%Y%m%d")
print(adj_date)
# 1. TODO: 筛选上市时间大于 1 年的股票
stock_info.list_date = pd.to_datetime(stock_info.list_date)
stock_info_1 = stock_info.loc[
(stock_info.list_date + pd.Timedelta(days=365)) < pd.Timestamp(adj_date)
]
# 2. FIXME: 筛选非 ST 股票,历史 ST 查询未完成
stock_info_2 = stock_info_1.loc[
~(stock_info_1.name.str.contains("ST") |
(stock_info_1.name.str.contains("退")))
]
# 3. TODO: 筛选之前一个月至少有 20 个交易日的股票
pre_adj_date = (pd.Timestamp(adj_date) -
pd.Timedelta(days=31)).strftime("%Y-%m-%d")
stock_len = (
QA.QA_fetch_stock_day_adv(
code=hc_fmt_symbol(stock_info_2.ts_code.to_list()),
start=pre_adj_date,
end=pd.Timestamp(adj_date).strftime("%Y-%m-%d"),
)
.data.groupby("code")
.apply(len)
)
stock_list = hc_fmt_symbol(
stock_len.loc[stock_len >= 15].index.tolist(), "ts")
)
.groupby("ts_code")
.apply(lambda x: x.loc[x.end_date == x.end_date.max()])
).droplevel(level=1).reset_index(drop=True).set_index(["ts_code", "end_date"])
)
.groupby("ts_code")
.apply(lambda x: x.loc[x.end_date == x.end_date.max()])
).droplevel(level=1).reset_index(drop=True).set_index(["ts_code", "end_date"])
cross_section_updated = cross_section_updated.loc[
cross_section_updated.index.intersection(cross_section.index)
]
print(cross_section_updated.head(3))
# 当前时间截面,如果有数据修正,进行更新
cross_section_updated = cross_section_updated.combine_first(cross_section)
results[adj_date] = cross_section_updated
测试,对应两个调仓日,获取柳工的财务数据的结果如下
处理代码:笔者这里采用了比较偷懒和取巧的处理方式,具体步骤如下历史所有类型所有财物数据获取并合并 import tushare as ts
import pandas as pd
import time
from utils import hc_get_report_date
ts.set_token("TUSHARE TOKEN")
pro = ts.pro_api()
# 设置报告期
report_dates_tail = ["0331", "0630", "0930", "1231"]
,,
).strftime("%Y%m%d").str.slice(0, 4))))
report_dates = [y + d for y in years for d in report_dates_tail]
for i in range(1, 13):
exec(f"df_income_{i} = pd.DataFrame()")
for report_date in report_dates:
print(report_date)
for report_type in range(1, 13):
try:
exec(
f"income_{report_type} = pro.income_vip(period={report_date}, report_type={report_type})")
except:
print(
"[WARNING]\t income type-{report_type} 接口错误, 当前报告期为 {report_date}, 等待 65 秒后重试")
time.sleep(65)
try:
exec(
f"income_{report_type} = pro.income_vip(period={report_date}, report_type={report_type}")
except:
raise ValueError("[ERROR]")
exec(f"print(income_{report_type})")
exec(
f"df_income_{report_type} = df_income_{report_type}.append(income_{report_type})")
for report_type in range(1, 13):
exec(
f"df_income_{report_type}.to_csv('../data/income_{report_type}.csv', index=False)")
调仓周期的设置,按照每月末调仓 # 考察日期设置
start_date = "2010-01-01"
end_date = "2020-10-17"
)
对应调仓日,能获取最新的财务数据 # 对每个调仓日进行查询,判断对应日期,应该获取的财报类型
# 说明:柳工 (000528.SZ) 在 2018 年 8 月 30 日发布半年报,之后在 2018 年 9 月 29 号发布
# 修正报告,在 tushare 对应的财报发布日期分别为
# report_date(报告期), ann_date(最新披露公告日) ,plan_date(计划公告日) ,actual_date(实际公告日) ,modify_date(披露日期修正记录)
# 20180630 ,20180629.0 ,20180830 ,20180830 ,NaN
# 20180930 ,20180928.0 ,20181030 ,20181030 ,NaN
# ...
# 20190630 ,20190628 ,20190829 ,20190829, NaN
# 当调仓日处于 20180830 ~ 20180928 之间的时候,财报获取类型为 type-5 (调整前合并报表 数据发生变更,将原数据进行保留,即调整前的原数据)
# 当调仓日处于 20180928 ~ 20190829 之间的时候,财报获取类型为 type-1 (上市公司最新报表(默认))
# 当调仓日处于 20190829 之后,财报获取类型为 type-4 (本年度公布上年同期的财务报表数据,报告期为上年度)
# FIXME: 例外情况:不定期财报修正可能出现在下下期财报发布之后,由此造成类型判断错位,暂时没想到比较好的解决方案
df_income = pd.read_csv(
"../data/income.csv", dtype={"ann_date": str, "f_ann_date": str, "end_date": str}
) # 这里的 income.csv 为合并后的所有财务数据
results = {}
# for adj_date in pos_adj_dates:
for adj_date in ["20180731", "20180831", "20180930", "20181031"]:
# adj_date = adj_date.strftime("%Y%m%d")
print(adj_date)
# 1. TODO: 筛选上市时间大于 1 年的股票
stock_info.list_date = pd.to_datetime(stock_info.list_date)
stock_info_1 = stock_info.loc[
(stock_info.list_date + pd.Timedelta(days=365)) < pd.Timestamp(adj_date)
]
# 2. FIXME: 筛选非 ST 股票,历史 ST 查询未完成
stock_info_2 = stock_info_1.loc[
~(stock_info_1.name.str.contains("ST") |
(stock_info_1.name.str.contains("退")))
]
# 3. TODO: 筛选之前一个月至少有 20 个交易日的股票
pre_adj_date = (pd.Timestamp(adj_date) -
pd.Timedelta(days=31)).strftime("%Y-%m-%d")
stock_len = (
QA.QA_fetch_stock_day_adv(
code=hc_fmt_symbol(stock_info_2.ts_code.to_list()),
start=pre_adj_date,
end=pd.Timestamp(adj_date).strftime("%Y-%m-%d"),
)
.data.groupby("code")
.apply(len)
)
stock_list = hc_fmt_symbol(
stock_len.loc[stock_len >= 15].index.tolist(), "ts")
)
.groupby("ts_code")
.apply(lambda x: x.loc[x.end_date == x.end_date.max()])
).droplevel(level=1).reset_index(drop=True).set_index(["ts_code", "end_date"])
)
.groupby("ts_code")
.apply(lambda x: x.loc[x.end_date == x.end_date.max()])
).droplevel(level=1).reset_index(drop=True).set_index(["ts_code", "end_date"])
cross_section_updated = cross_section_updated.loc[
cross_section_updated.index.intersection(cross_section.index)
]
print(cross_section_updated.head(3))
# 当前时间截面,如果有数据修正,进行更新
cross_section_updated = cross_section_updated.combine_first(cross_section)
results[adj_date] = cross_section_updated
测试,对应两个调仓日,获取柳工的财务数据的结果如下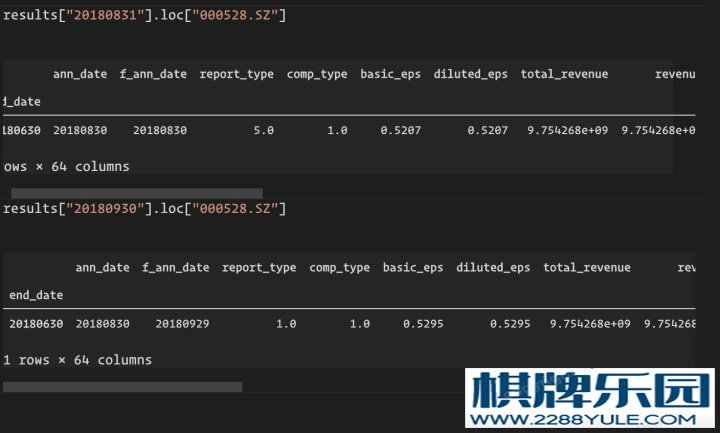 Footnotes1 原本笔者准备按照上市公司财报发布时间进行数据查找,但是全市场股票太多,数据接口限制太大,因此该工具函数仅供参考,更方便的方式,还是将所有上市公司的财务数据下载到本地处理,更为方便
Footnotes1 原本笔者准备按照上市公司财报发布时间进行数据查找,但是全市场股票太多,数据接口限制太大,因此该工具函数仅供参考,更方便的方式,还是将所有上市公司的财务数据下载到本地处理,更为方便
处理代码:笔者这里采用了比较偷懒和取巧的处理方式,具体步骤如下历史所有类型所有财物数据获取并合并 import tushare as ts
import pandas as pd
import time
from utils import hc_get_report_date
ts.set_token("TUSHARE TOKEN")
pro = ts.pro_api()
# 设置报告期
report_dates_tail = ["0331", "0630", "0930", "1231"]
,,
).strftime("%Y%m%d").str.slice(0, 4))))
report_dates = [y + d for y in years for d in report_dates_tail]
for i in range(1, 13):
exec(f"df_income_{i} = pd.DataFrame()")
for report_date in report_dates:
print(report_date)
for report_type in range(1, 13):
try:
exec(
f"income_{report_type} = pro.income_vip(period={report_date}, report_type={report_type})")
except:
print(
"[WARNING]\t income type-{report_type} 接口错误, 当前报告期为 {report_date}, 等待 65 秒后重试")
time.sleep(65)
try:
exec(
f"income_{report_type} = pro.income_vip(period={report_date}, report_type={report_type}")
except:
raise ValueError("[ERROR]")
exec(f"print(income_{report_type})")
exec(
f"df_income_{report_type} = df_income_{report_type}.append(income_{report_type})")
for report_type in range(1, 13):
exec(
f"df_income_{report_type}.to_csv('../data/income_{report_type}.csv', index=False)")
调仓周期的设置,按照每月末调仓 # 考察日期设置
start_date = "2010-01-01"
end_date = "2020-10-17"
)
对应调仓日,能获取最新的财务数据 # 对每个调仓日进行查询,判断对应日期,应该获取的财报类型
# 说明:柳工 (000528.SZ) 在 2018 年 8 月 30 日发布半年报,之后在 2018 年 9 月 29 号发布
# 修正报告,在 tushare 对应的财报发布日期分别为
# report_date(报告期), ann_date(最新披露公告日) ,plan_date(计划公告日) ,actual_date(实际公告日) ,modify_date(披露日期修正记录)
# 20180630 ,20180629.0 ,20180830 ,20180830 ,NaN
# 20180930 ,20180928.0 ,20181030 ,20181030 ,NaN
# ...
# 20190630 ,20190628 ,20190829 ,20190829, NaN
# 当调仓日处于 20180830 ~ 20180928 之间的时候,财报获取类型为 type-5 (调整前合并报表 数据发生变更,将原数据进行保留,即调整前的原数据)
# 当调仓日处于 20180928 ~ 20190829 之间的时候,财报获取类型为 type-1 (上市公司最新报表(默认))
# 当调仓日处于 20190829 之后,财报获取类型为 type-4 (本年度公布上年同期的财务报表数据,报告期为上年度)
# FIXME: 例外情况:不定期财报修正可能出现在下下期财报发布之后,由此造成类型判断错位,暂时没想到比较好的解决方案
df_income = pd.read_csv(
"../data/income.csv", dtype={"ann_date": str, "f_ann_date": str, "end_date": str}
) # 这里的 income.csv 为合并后的所有财务数据
results = {}
# for adj_date in pos_adj_dates:
for adj_date in ["20180731", "20180831", "20180930", "20181031"]:
# adj_date = adj_date.strftime("%Y%m%d")
print(adj_date)
# 1. TODO: 筛选上市时间大于 1 年的股票
stock_info.list_date = pd.to_datetime(stock_info.list_date)
stock_info_1 = stock_info.loc[
(stock_info.list_date + pd.Timedelta(days=365)) < pd.Timestamp(adj_date)
]
# 2. FIXME: 筛选非 ST 股票,历史 ST 查询未完成
stock_info_2 = stock_info_1.loc[
~(stock_info_1.name.str.contains("ST") |
(stock_info_1.name.str.contains("退")))
]
# 3. TODO: 筛选之前一个月至少有 20 个交易日的股票
pre_adj_date = (pd.Timestamp(adj_date) -
pd.Timedelta(days=31)).strftime("%Y-%m-%d")
stock_len = (
QA.QA_fetch_stock_day_adv(
code=hc_fmt_symbol(stock_info_2.ts_code.to_list()),
start=pre_adj_date,
end=pd.Timestamp(adj_date).strftime("%Y-%m-%d"),
)
.data.groupby("code")
.apply(len)
)
stock_list = hc_fmt_symbol(
stock_len.loc[stock_len >= 15].index.tolist(), "ts")
)
.groupby("ts_code")
.apply(lambda x: x.loc[x.end_date == x.end_date.max()])
).droplevel(level=1).reset_index(drop=True).set_index(["ts_code", "end_date"])
)
.groupby("ts_code")
.apply(lambda x: x.loc[x.end_date == x.end_date.max()])
).droplevel(level=1).reset_index(drop=True).set_index(["ts_code", "end_date"])
cross_section_updated = cross_section_updated.loc[
cross_section_updated.index.intersection(cross_section.index)
]
print(cross_section_updated.head(3))
# 当前时间截面,如果有数据修正,进行更新
cross_section_updated = cross_section_updated.combine_first(cross_section)
results[adj_date] = cross_section_updated
测试,对应两个调仓日,获取柳工的财务数据的结果如下Footnotes1 原本笔者准备按照上市公司财报发布时间进行数据查找,但是全市场股票太多,数据接口限制太大,因此该工具函数仅供参考,更方便的方式,还是将所有上市公司的财务数据下载到本地处理,更为方便
若是要在游戏中出千的话,需要保障人们的出手速度要快,要避免被其他的玩家给察觉。要能够做到随意换牌或是从背面就能够知道牌的点数和花色很不容易,所以可以知道要学习出千技术的辛苦。一般的人们都是可以就麻将斗牛好好的感受,当作好的休闲方式。
2三.该页面会显示设备上的所用应用.移动应用名字右侧的开关.可开启/关闭加速功能,


