





棋牌问答 有人用机器学习来赌香港赛马并且成功赢钱的吗
发布日期:2022-03-12 20:05 点击次数:143
不请自来。这个问题的回答水平之低令人发指,可能确实如上面有人所说,真正开发出好的模型的人都在闷声发大财吧。我因为做过一点研究,希望能在这里抛砖引玉一下。版权所有,请勿转载。 ==================================================0、基础知识: 在开始讨论模型之前,我们需要先了解一下赛马/赌马。香港的马赛是一周两场,周三和周六/周日。每个比赛日有8-11场比赛。每场比赛参赛的马匹数量不等,一般在8-14匹。 赛马比赛中比较关键的两个角色是马和骑师。每一匹马在每个比赛日最多只能参加一场比赛,而骑师则可以参加多场比赛(这个很重要)。当然还有一个比较重要的角色是训练师,但相比于马和骑师来说重要性要小一些。 赌马的玩法有很多种,比较常见的是买独赢(Win)和位置(Place)。独赢(Win)指的是买第一名的马,也就是说只有你买的马跑了第一名才算赢。而位置(Place)指的是买前三名,也就是只要你买的马跑了前三名,你就有钱拿。为了方便起见,我们下面只讨论独赢(Win)。 场内下注以HKD 10为最小单位,而最终的赔率以当场最终全部下注为准。这里关于赔率的计算就不展开了,但是并不是像很多人所说的是靠精算师用复杂的模型算出来的,因为我们讨论的不是一个独立庄家的盘口,而是场内马会自己的赔率。按照马会的公告,每场比赛的奖池抽水17%之后,剩下的与单一注码的下注金额的比例,就是这个注的最终赔率。这里需要注意的是抽水的17%。因为马会的抽水决定了对于每场比赛下注的所有人来说,这其实不是一个零和游戏,而是一个负和游戏。而且如果你把每场比赛的最终赔率换算过来,会发现马会每场的抽水也不是固定的,基本在17%-19%之间,具体原因我也没有深究过。 好了,知道了这些之后,这个游戏其实就很明白了,你的策略就是选择能够给你带来预期正收益的马去下注。什么?你不知道什么叫预期正收益?那我觉得你就没必要往下看了。。。 好吧,预期正收益就是指: 获胜概率(p)*赔率(odds) > 1 上面这个公式是所有策略的核心。它告诉我们,并不是越热门的马越好(因为获胜概率虽然可能很高,但是赔率可能不合算),也不是赔率越高的马越好(获胜概率可能极低)。 1、巨人肩膀 好了,知道了上面的基本知识之后,咱们就可以来讨论一下这个问题本身了。首先,我建议把问题中的“机器学习”改成“量化模型”。Machine Learning虽然是现在很火的概念,但是其本质还是量化的模型,也就是通过数据+模型的方法来进行预测。从这个意义上来说,传统统计模型也是一样的。更重要的是,我下面要介绍的这位,用的就不是什么花哨的ML模型。铺垫结束,下面隆重请出这位传奇人物: William Benter (关于他的生平之类的,我就不在这里介绍了,相信大家挖掘八卦的能力比我要强)。这里我们重点来分享一下他的一篇文章: Computer-based horse race handicapping and wagering systems: A report 话说William大哥在香港靠模型赌马赢了不少钱之后,不忘自己一个学者的本份,把自己的模型系统写成了一个报告,就是上面这篇。这篇报告发表在1994年,后来还有很多的学者在此基础之上开发新的、更为炫酷的模型,但不得不说,William的这篇可以说是真正意义上的开山之作。 这里先给大家展示一下William模型的盈利效果(纵轴是取了Log的哦):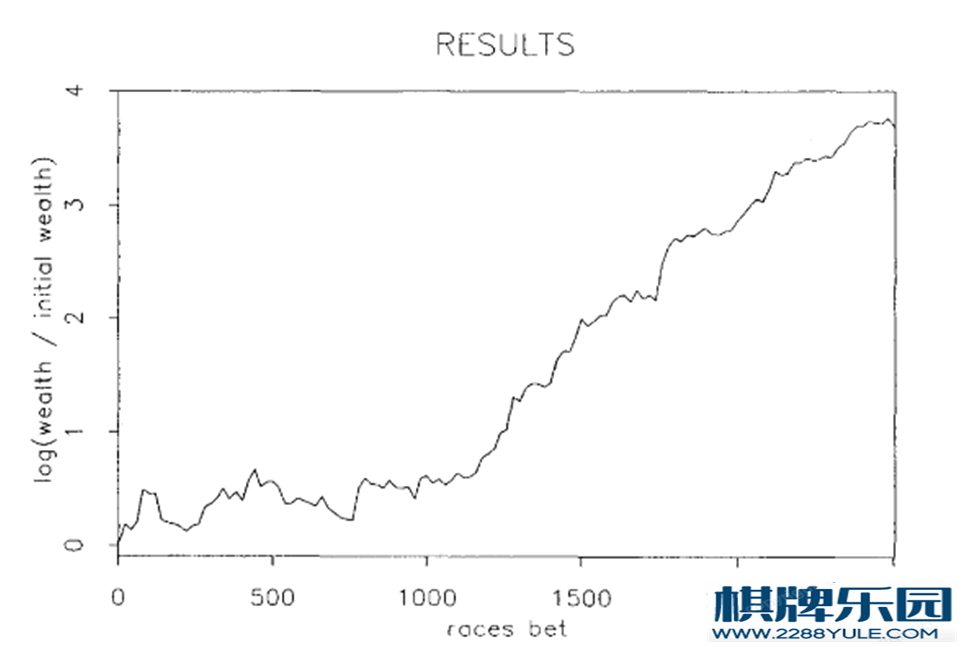
 2、模型思路 William模型中有很多的细节,我这里就不一一展开了。我只讲我认为最重要或者说最有意义的几个点。2.1 Conditional Multinomial Logistic Model 首先,每一场比赛都是一个独立的竞争性事件。也就是说,每一只马要做的,是打败同组的其他马获得冠军。这个特点决定了我们应该关心的是马的相对表现(relative performance)而不是绝对表现(absolute performance)。我们怎么来model一个相对事件的概率?相信玩过(multinomial)logistic regression model的都知道,这些模型就是为competing events建模而生的。但这里最大的问题是,我们需要以每场比赛为一个单位进行likelihood的计算,这个跟传统的logistic regression计算方法是不一样的,所以就用到了Conditional Multinomial Logistic Model。至于模型的具体细节,大家就自己去看paper吧。 2.2 封闭的数据集 我个人认为William的报告另一个重要的启示,在于模型数据的选择。他提出的一个概念是封闭的数据集(closed)。什么意思呢?就是说凡出现在你的模型训练数据集中的马,你的数据集要覆盖他所有的比赛历史场次。这一点其实是很重要的,至少对于当前在役的马,你要保证你的数据集当中包括他们所有的历史数据。 2.3 两阶段模型(two-stage model) 你开发出了一个模型(不管是ML模型,还是Logistic,哪怕是简单的线性模型),怎么来判断这个模型有多少价值?在进行实盘回测之前,可以先把你模型的预测结果,跟赔率隐含的概率(odds implied winning probabilities)来一个logit 回归分析,看看你的模型预测和赔率隐含概率(代表的是大众/市场对比赛的看法)哪个对最终的结果贡献更大。 我个人觉得这真是一个非常巧妙的方法。说白了你的模型是不可能考虑到所有的影响因素的,那么你没考虑到的因素可能在赔率当中有所体现(赔率可以看成是所有人用下注来进行的投票)。这个logit回归出来的结果中,你的模型结果的系数越高,说明你的模型贡献越大(越准确)。 这个logit模型的结果,也可以用在后面你进行预测的时候,作为第二阶段的模型。也就是将第一步你自己模型的预测结果加上赔率的信息得到最终的预测结果。 2.4 特征工程(feature engineering) 上面的几点虽然巧妙,但是真正花时间的还是构建各种变量。这里我就直接贴一下William的几大类解释变量好了:
2、模型思路 William模型中有很多的细节,我这里就不一一展开了。我只讲我认为最重要或者说最有意义的几个点。2.1 Conditional Multinomial Logistic Model 首先,每一场比赛都是一个独立的竞争性事件。也就是说,每一只马要做的,是打败同组的其他马获得冠军。这个特点决定了我们应该关心的是马的相对表现(relative performance)而不是绝对表现(absolute performance)。我们怎么来model一个相对事件的概率?相信玩过(multinomial)logistic regression model的都知道,这些模型就是为competing events建模而生的。但这里最大的问题是,我们需要以每场比赛为一个单位进行likelihood的计算,这个跟传统的logistic regression计算方法是不一样的,所以就用到了Conditional Multinomial Logistic Model。至于模型的具体细节,大家就自己去看paper吧。 2.2 封闭的数据集 我个人认为William的报告另一个重要的启示,在于模型数据的选择。他提出的一个概念是封闭的数据集(closed)。什么意思呢?就是说凡出现在你的模型训练数据集中的马,你的数据集要覆盖他所有的比赛历史场次。这一点其实是很重要的,至少对于当前在役的马,你要保证你的数据集当中包括他们所有的历史数据。 2.3 两阶段模型(two-stage model) 你开发出了一个模型(不管是ML模型,还是Logistic,哪怕是简单的线性模型),怎么来判断这个模型有多少价值?在进行实盘回测之前,可以先把你模型的预测结果,跟赔率隐含的概率(odds implied winning probabilities)来一个logit 回归分析,看看你的模型预测和赔率隐含概率(代表的是大众/市场对比赛的看法)哪个对最终的结果贡献更大。 我个人觉得这真是一个非常巧妙的方法。说白了你的模型是不可能考虑到所有的影响因素的,那么你没考虑到的因素可能在赔率当中有所体现(赔率可以看成是所有人用下注来进行的投票)。这个logit回归出来的结果中,你的模型结果的系数越高,说明你的模型贡献越大(越准确)。 这个logit模型的结果,也可以用在后面你进行预测的时候,作为第二阶段的模型。也就是将第一步你自己模型的预测结果加上赔率的信息得到最终的预测结果。 2.4 特征工程(feature engineering) 上面的几点虽然巧妙,但是真正花时间的还是构建各种变量。这里我就直接贴一下William的几大类解释变量好了:
 这些变量肯定是通过千锤百炼总结出来的,而且具体每个变量的构建方法、是否线性等等,都是需要建模者自己去探索的。 好了,说到这里,基本上核心的内容就都讲到了。如果你手头刚好搜集了一定的数据,那么你就可以开始入手搭建一个量化模型了。什么?你懒得去搜集数据? 服了你了。。下面这个链接来自Kaggle,也不知道这个哥们的数据来源是不是可靠,但至少能让你get started了吧?(以后赚了钱记得感谢一下我哈哈) https://www.kaggle.com/gdaley/hkracing
这些变量肯定是通过千锤百炼总结出来的,而且具体每个变量的构建方法、是否线性等等,都是需要建模者自己去探索的。 好了,说到这里,基本上核心的内容就都讲到了。如果你手头刚好搜集了一定的数据,那么你就可以开始入手搭建一个量化模型了。什么?你懒得去搜集数据? 服了你了。。下面这个链接来自Kaggle,也不知道这个哥们的数据来源是不是可靠,但至少能让你get started了吧?(以后赚了钱记得感谢一下我哈哈) https://www.kaggle.com/gdaley/hkracing
2、模型思路 William模型中有很多的细节,我这里就不一一展开了。我只讲我认为最重要或者说最有意义的几个点。2.1 Conditional Multinomial Logistic Model 首先,每一场比赛都是一个独立的竞争性事件。也就是说,每一只马要做的,是打败同组的其他马获得冠军。这个特点决定了我们应该关心的是马的相对表现(relative performance)而不是绝对表现(absolute performance)。我们怎么来model一个相对事件的概率?相信玩过(multinomial)logistic regression model的都知道,这些模型就是为competing events建模而生的。但这里最大的问题是,我们需要以每场比赛为一个单位进行likelihood的计算,这个跟传统的logistic regression计算方法是不一样的,所以就用到了Conditional Multinomial Logistic Model。至于模型的具体细节,大家就自己去看paper吧。 2.2 封闭的数据集 我个人认为William的报告另一个重要的启示,在于模型数据的选择。他提出的一个概念是封闭的数据集(closed)。什么意思呢?就是说凡出现在你的模型训练数据集中的马,你的数据集要覆盖他所有的比赛历史场次。这一点其实是很重要的,至少对于当前在役的马,你要保证你的数据集当中包括他们所有的历史数据。 2.3 两阶段模型(two-stage model) 你开发出了一个模型(不管是ML模型,还是Logistic,哪怕是简单的线性模型),怎么来判断这个模型有多少价值?在进行实盘回测之前,可以先把你模型的预测结果,跟赔率隐含的概率(odds implied winning probabilities)来一个logit 回归分析,看看你的模型预测和赔率隐含概率(代表的是大众/市场对比赛的看法)哪个对最终的结果贡献更大。 我个人觉得这真是一个非常巧妙的方法。说白了你的模型是不可能考虑到所有的影响因素的,那么你没考虑到的因素可能在赔率当中有所体现(赔率可以看成是所有人用下注来进行的投票)。这个logit回归出来的结果中,你的模型结果的系数越高,说明你的模型贡献越大(越准确)。 这个logit模型的结果,也可以用在后面你进行预测的时候,作为第二阶段的模型。也就是将第一步你自己模型的预测结果加上赔率的信息得到最终的预测结果。 2.4 特征工程(feature engineering) 上面的几点虽然巧妙,但是真正花时间的还是构建各种变量。这里我就直接贴一下William的几大类解释变量好了:这些变量肯定是通过千锤百炼总结出来的,而且具体每个变量的构建方法、是否线性等等,都是需要建模者自己去探索的。 好了,说到这里,基本上核心的内容就都讲到了。如果你手头刚好搜集了一定的数据,那么你就可以开始入手搭建一个量化模型了。什么?你懒得去搜集数据? 服了你了。。下面这个链接来自Kaggle,也不知道这个哥们的数据来源是不是可靠,但至少能让你get started了吧?(以后赚了钱记得感谢一下我哈哈) https://www.kaggle.com/gdaley/hkracing
如果你此时觉得无聊的话,那么就来一盘打麻将吧,这不仅能让你更加体验生活中所带来的不同,好好去享受生活吧,不过玩麻将也是一种享受,如果你此时也走兴趣玩的话,那么现在就去体验一番把!这不会像网络游戏那样让你深刻沉迷,它会让你从中得到启示,让你作为一种爱好来娱乐,这是它最具有特色的地方了。如果你此时需要做点事情来打发时间的话棋牌问答,那你就应该去玩一下麻将,这会让你觉得时间原来也是那么好过的,这么多的好处棋牌问答,你是否都记得了,那么就进来玩两把吧!


